Abstract
The widespread adoption of large language models (LLMs) necessitates reliable methods to detect LLM-generated text. We introduce SimMark, a robust sentence-level watermarking algorithm that makes LLMs' outputs traceable without requiring access to model internals, making it compatible with both open and API-based LLMs. By leveraging the similarity of semantic sentence embeddings combined with rejection sampling to embed detectable statistical patterns imperceptible to humans, and employing a soft counting mechanism, SimMark achieves robustness against paraphrasing attacks. Experimental results demonstrate that SimMark sets a new benchmark for robust watermarking of LLM-generated content, surpassing prior sentence-level watermarking techniques in robustness, sampling efficiency, and applicability across diverse domains, all while maintaining the text quality and fluency.
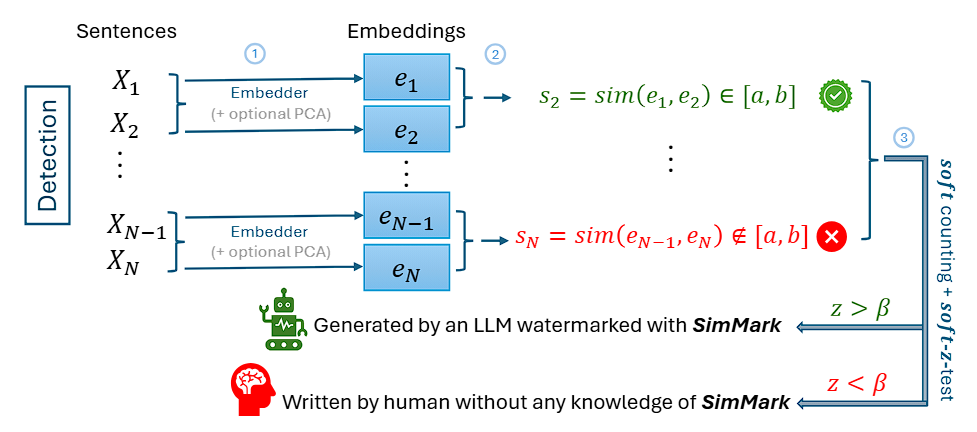
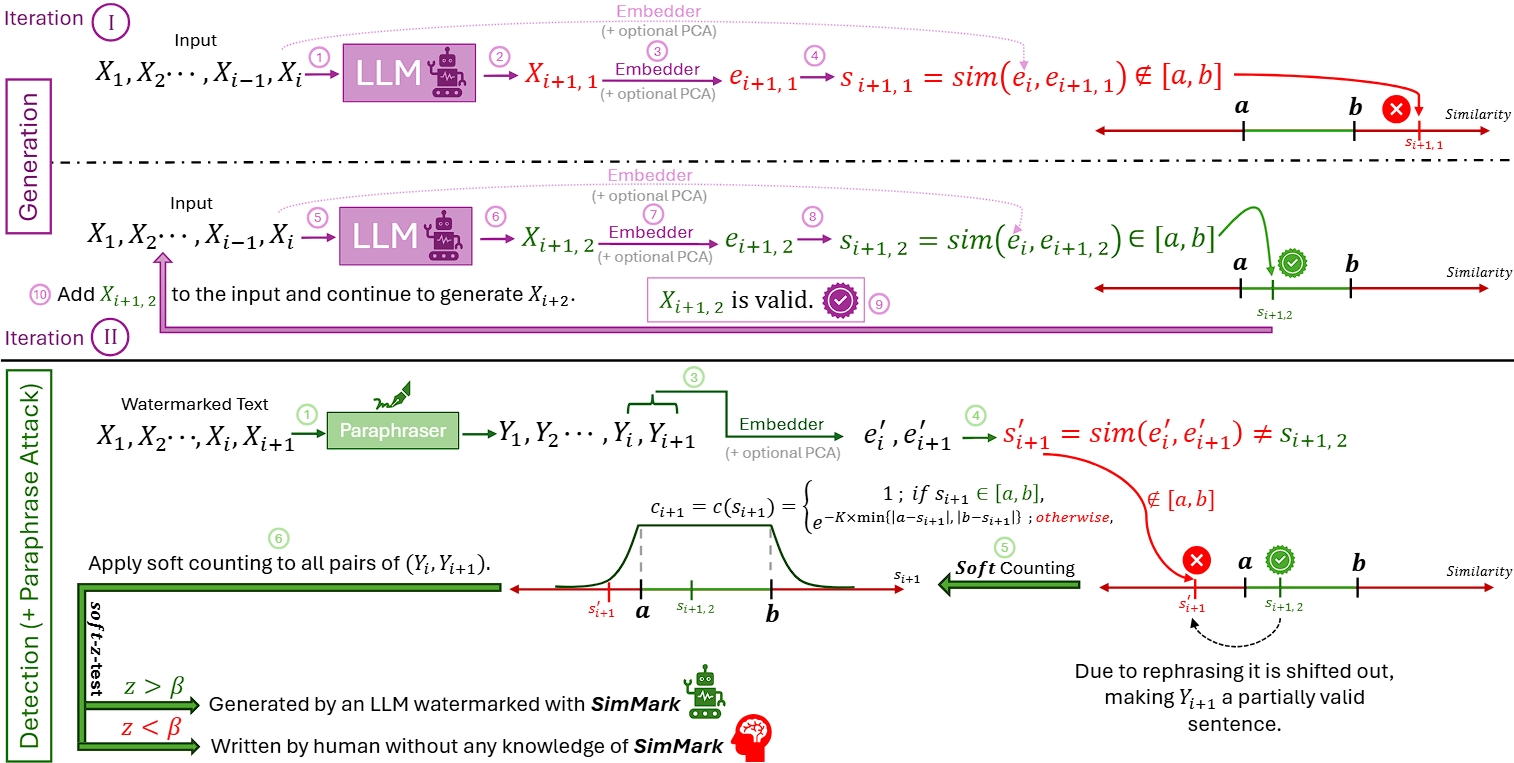
Overview of SimMark: A Similarity-Based Watermark
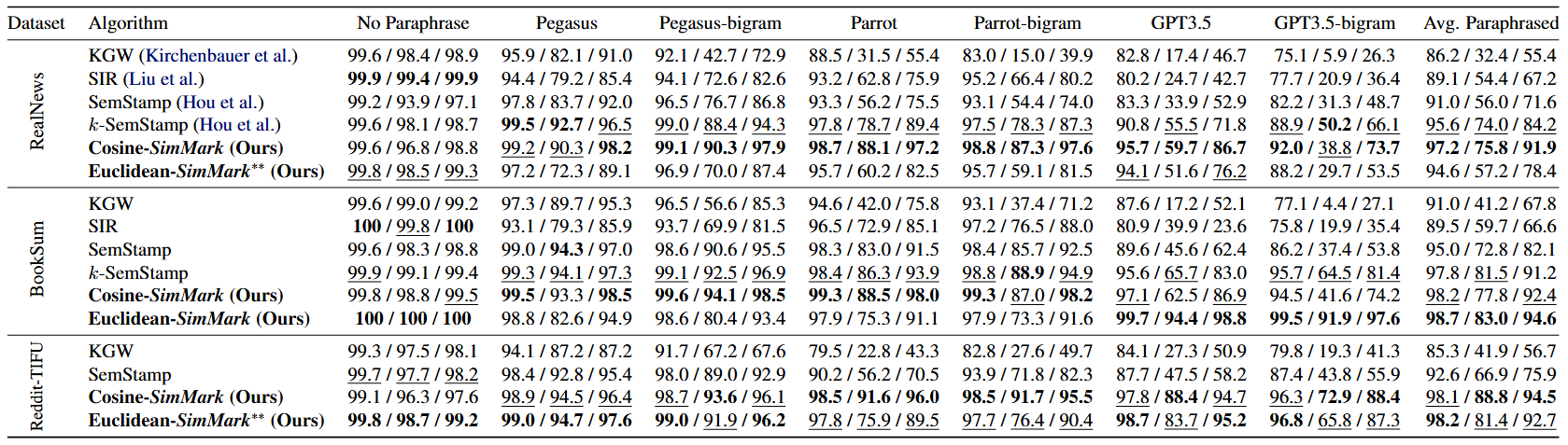
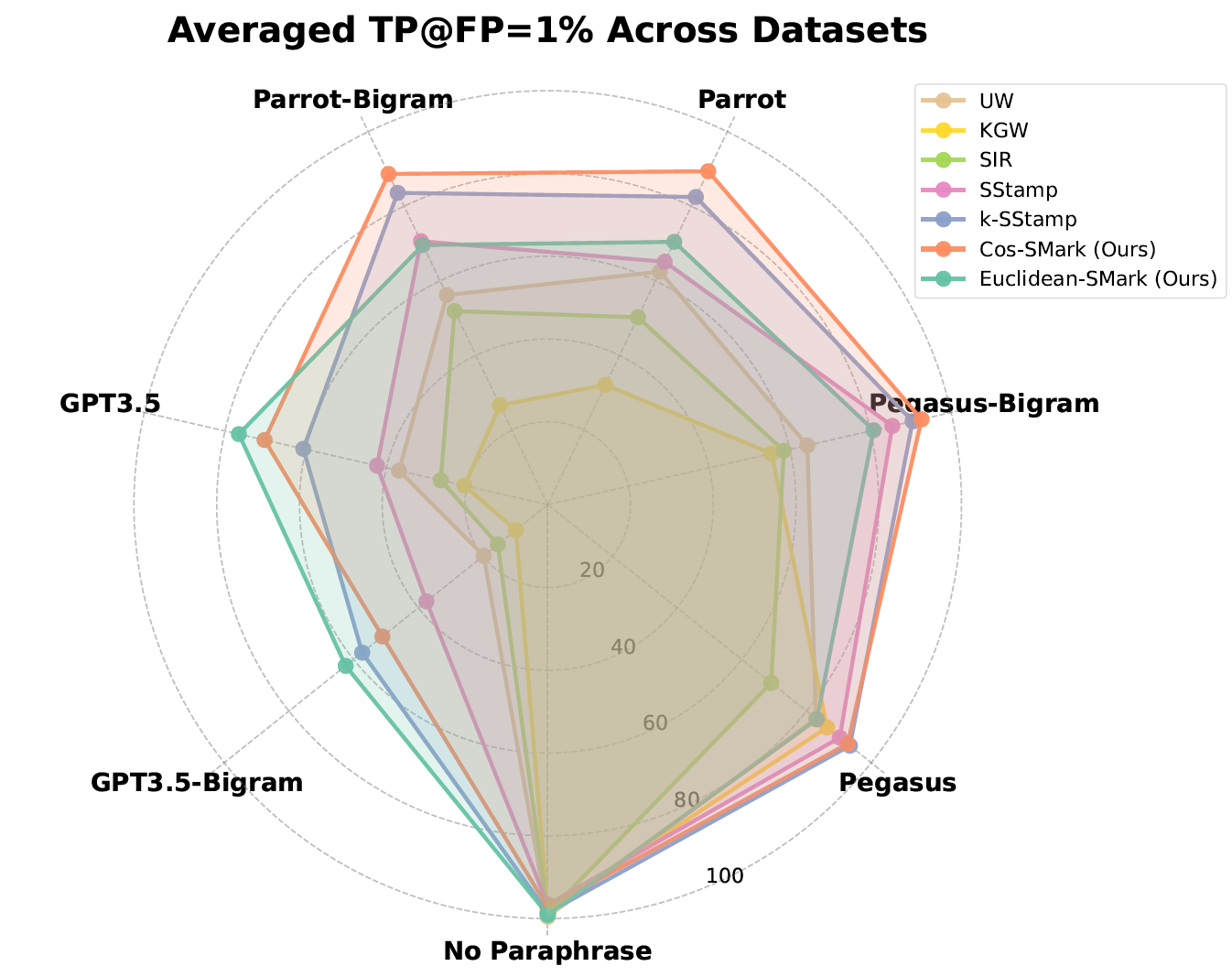
Detection Performance
Examples of Watermarked Text


BibTeX
If you found this work helpful, please don't forget to cite our paper:@misc{dabiriaghdam2025simmarkrobustsentencelevelsimilaritybased,
title={SimMark: A Robust Sentence-Level Similarity-Based Watermarking Algorithm for Large Language Models},
author={Amirhossein Dabiriaghdam and Lele Wang},
year={2025},
eprint={2502.02787},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.02787},
}